类加载过程
加载->验证->准备->解析->初始化
- 加载:通过一个类的完全限定查找此类字节码文件,并利用字节码文件创建一个Class对象。
- 验证:文件格式验证,元数据验证,字节码验证,符号引用验证。
- 准备:为类变量(即static修饰的字段变量)分配内存并且设置该类变量的初始值即0(如static int i=5;这里只将i初始化为0,至于5的值将在初始化时赋值),这里不包含用final修饰的static,因为final在编译的时候就会分配了,注意这里不会为实例变量分配初始化,类变量会分配在方法区中,而实例变量是会随着对象一起分配到Java堆中。
- 解析:主要将常量池中的符号引用替换为直接引用的过程。符号引用就是一组符号来描述目标,可以是任何字面量,而直接引用就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。有类或接口的解析,字段解析,类方法解析,接口方法解析(这里涉及到字节码变量的引用。
- 初始化:类加载最后阶段,若该类具有超类,则对其进行初始化,执行静态初始化器和静态初始化成员变量(如前面只初始化了默认值的static变量将会在这个阶段赋值,成员变量也将被初始化)。
- 使用
- 卸载
类加载器
启动(Bootstrap)
- c++ 实现,所以在java代码中get体现为null。负责将 Java_Home/lib下面的类库加载到内存中(比如rt.jar)。
扩展(Extension)
- 是由 Sun 的 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的。它负责将Java_Home /lib/ext或者由系统变量 java.ext.dir指定位置中的类库加载到内存中。
系统(App)
- 是由 Sun 的 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的。它负责将系统类路径(CLASSPATH)中指定的类库加载到内存中。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,因此一般称为系统(System)加载器。
自定义(Custom)
- 开发者自己定义 +自定义只需继承ClassLoader类,重写findClass方法。其中可使用defineClass方法将class文件的二进制byte数组转化为class类 +自定义类加载器加载自加密的class,可防止反编译,防止篡改
-
parent是如何指定的,打破双亲委派
- 用super(parent)指定
- 双亲委派的打破
- 如何打破:重写loadClass()
- 何时打破过?
- JDK1.2之前,自定义ClassLoader都必须重写loadClass()
- ThreadContextClassLoader可以实现基础类调用实现类代码,通过thread.setContextClassLoader指定
- 热启动,热部署
- osgi tomcat 都有自己的模块指定classloader(可以加载同一类库的不同版本)
双亲委派模型
- 出于安全考虑。首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
Object o = new Obejct() 的半初始化问题
0 new #2 <java/lang/Object>
3 dup
4 invokespecial #1 <java/lang/Object.<init>>
7 astore_1
8 return
- 发生指令重排序,astore_1 如果在 invokespecial 前执行,就会产生引用到空内存的未初始化对象。
内存屏障
inter x86 架构 cpu 硬件级实现
- Lfence 前后都是 load 的屏障
- Sfence 前后都是 save 的屏障
- Mfence 前后任意 的屏障
jvm 内存屏障
- LoadStore 前 load 后 store
- LoadLoad
- StoreLoad
- StoreStore
volatile 各层次实现
字节码层面(class文件)
- 仅仅增加一行 ACC_VOLATILE 具体实现由jvm决定
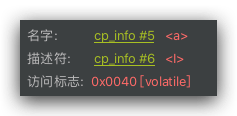
jvm 实现
-
StoreStore volatile写 StoreLoad - volatile读 | LoadLoad | LoadStore
硬件
- X86 : lock cmpxchg 实现
对象
对象的创建过程
- 类的加载:加载,验证,准备,解析,初始化 + 对象创建:分配内存,成员变量赋默认值,调用构造方法
(成员变量顺序赋初始值,调用构造方法) 对象的内存布局
普通对象
- 对象头 mark word 8字节
- 对象头 klass pointer指针 -XX:-UseCompressedOops 为4字节,否则为8字节
- 实例数据 引用类型:-XX:+UseCompressedOops 为4字节 不开启为8字节(Oops Ordinary Object Pointers 普通对象的指针)
- pending 对齐,8的倍数
数组对象
- 对象头中多了一个 数组长度 4字节
对象头的具体
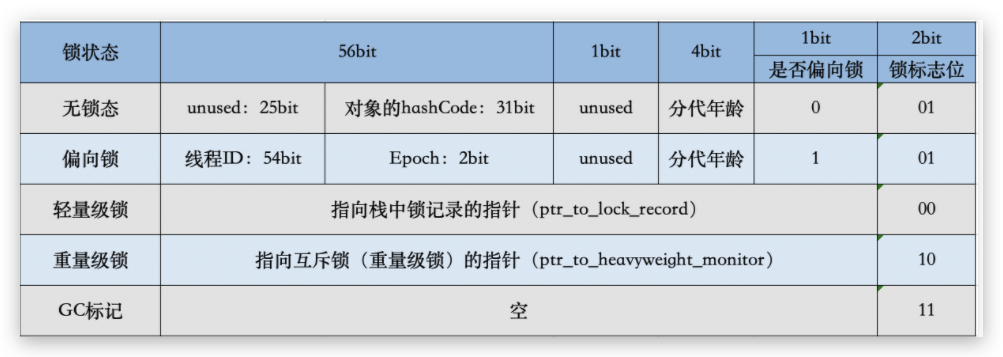
- gc分代最大只能15 因为只有4位
使用JavaAgent测试Object的大小
观察虚拟机配置
java -XX:+PrintCommandLineFlags -version
实验
-
新建项目ObjectSize (1.8)
-
创建文件ObjectSizeAgent
package com.mashibing.jvm.agent; import java.lang.instrument.Instrumentation; public class ObjectSizeAgent { private static Instrumentation inst; public static void premain(String agentArgs, Instrumentation _inst) { inst = _inst; } public static long sizeOf(Object o) { return inst.getObjectSize(o); } } -
src目录下创建META-INF/MANIFEST.MF
Manifest-Version: 1.0 Created-By: mashibing.com Premain-Class: com.mashibing.jvm.agent.ObjectSizeAgent注意Premain-Class这行必须是新的一行(回车 + 换行),确认idea不能有任何错误提示
-
打包jar文件
-
在需要使用该Agent Jar的项目中引入该Jar包
- 运行时需要该Agent Jar的类,加入参数:
-javaagent:C:\work\ijprojects\ObjectSize\out\artifacts\ObjectSize_jar\ObjectSize.jar -
如何使用该类:
import com.jvm.agent.ObjectSizeAgent; public class T03_SizeOfAnObject { public static void main(String[] args) { System.out.println(ObjectSizeAgent.sizeOf(new Object())); System.out.println(ObjectSizeAgent.sizeOf(new int[] {})); System.out.println(ObjectSizeAgent.sizeOf(new P())); } private static class P { //8 _markword //4 _oop指针 int id; //4 String name; //4 int age; //4 byte b1; //1 byte b2; //1 Object o; //4 byte b3; //1 } }
5: 运行时数据区Runtime Data Area
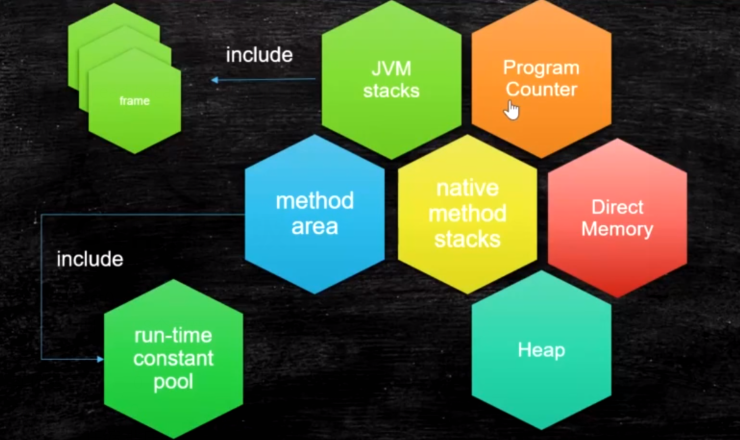
PC 程序计数器
- PC 寄存器,也叫程序计数器。JVM支持多个线程同时运行,每个线程都有自己的程序计数器。倘若当前执行的是 JVM 的方法,则该寄存器中保存当前执行指令的地址;倘若执行的是native 方法,则PC寄存器中为空。
native method stacks
- java调用的JNI,c和c++写的 这部分主要与虚拟机用到的 Native 方法相关
jvm stacks
- 每个线程对应一个栈,每个方法对应一个栈帧
- 栈里面存着的是一种叫“栈帧”的东西,每个方法会创建一个栈帧,栈帧中存放了局部变量表(基本数据类型和对象引用)、操作数栈、方法出口等信息。栈的大小可以固定也可以动态扩展。当栈调用深度大于JVM所允许的范围,会抛出StackOverflowError的错误,
栈帧 Frame
- Local variable Table 局部变量表
- Operand Stack 操作数栈 对于long的处理(store and load),多数虚拟机的实现都是原子的 jls 17.7,没必要加volatile
- Dynamic Linking 指向常量池
- return address 存放返回值
a() -> b(),方法a调用了方法b, b方法的返回值放在什么地方
heap 堆
- 堆内存是 JVM 所有线程共享的部分,在虚拟机启动的时候就已经创建。所有的对象和数组都在堆上进行分配。这部分空间可通过 GC 进行回收。当申请不到空间时会抛出 OutOfMemoryError。
Direct memory
- 直接内存,由操作系统管理,用于访问内核空间内存
- JVM可以直接访问的内核空间的内存 (OS 管理的内存)
- NIO, 提高效率,实现zero copy
method area 装常量池,存储每个class的结构
- 主要用于存储类的信息、常量池、方法数据、方法代码等。方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。
- Perm Space (<1.8) 永久代 字符串常量位于PermSpace FGC不会清理 大小启动的时候指定,不能变
- Meta Space (>=1.8) 字符串常量位于堆 会触发FGC清理 不设定的话,最大就是物理内存
常用指令
- store
- load
- pop
- mul
- sub
- invoke
- InvokeStatic
- InvokeVirtual
- InvokeInterface
- InovkeSpecial, 可以直接定位,不需要多态的方法: private 方法,构造方法
- InvokeDynamic,JVM最难的指令,lambda表达式或者反射或者其他动态语言scala kotlin,或者CGLib ASM,动态产生的class,会用到的指令
GC
1. 什么是垃圾
- 没有任何引用指向的一个对象或者多个对象(循环引用)
2. 如何定位垃圾
- 引用计数 reference count
对象内会记录有多少个引用指向,引用数量为0时成为垃圾,但对象之间循环引用时,比如a引用b,b引用c,c引用a时,无法回收
- 根可达算法 Root Searching
没有与根有引用连接的对象为垃圾
根有哪些?
JVM Stack,native method stack ,run-time constant pool ,static references in method area,Clazz
比如线程栈变量,静态变量,常量池,JNI变量
3.常见的垃圾回收算法
-
标记清除(mark sweep) - 先扫描一边,将垃圾标记出来,第二次扫描把标记为垃圾的对象清除,不移动对象位置
位置不连续 产生碎片 需要两遍扫描,效率偏低
算法相对简单,存活对象比较多的情况下率高
-
拷贝算法 (copying) - 扫描对象,将有用对象复制到另一块内存,剩下的垃圾整个清除
没有碎片,浪费空间,移动复制对象,需要调整对象引用
适用于存活对象较少的情况,只扫描一遍,效率提高,没有碎片。
-
标记压缩(mark compact) - 把有用对象移动到一起,垃圾直接清理
没有碎片,效率偏低(两遍扫描,指针需要调整)
不会产生碎片,方便对象分配,不会产生内存减半
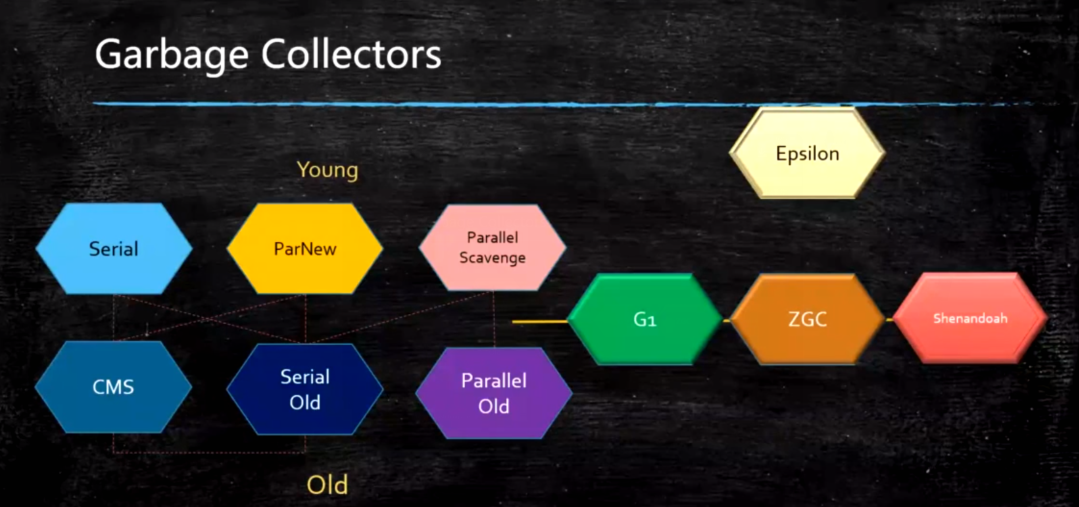
4.JVM内存分代模型(用于分代垃圾回收算法)
-
部分垃圾回收器使用的模型
除Epsilon ZGC Shenandoah之外的GC都是使用逻辑分代模型
G1是逻辑分代,物理不分代
除此之外不仅逻辑分代,而且物理分代
-
新生代 + 老年代 + 永久代(1.7)Perm Generation/ 元数据区(1.8) Metaspace
- 永久代 元数据区 - Class
- 永久代必须指定大小限制 ,元数据可以设置,也可以不设置,无上限(受限于物理内存)
- 字符串常量 1.7 - 永久代,1.8 - 堆
- MethodArea逻辑概念 - 永久代、元数据
-
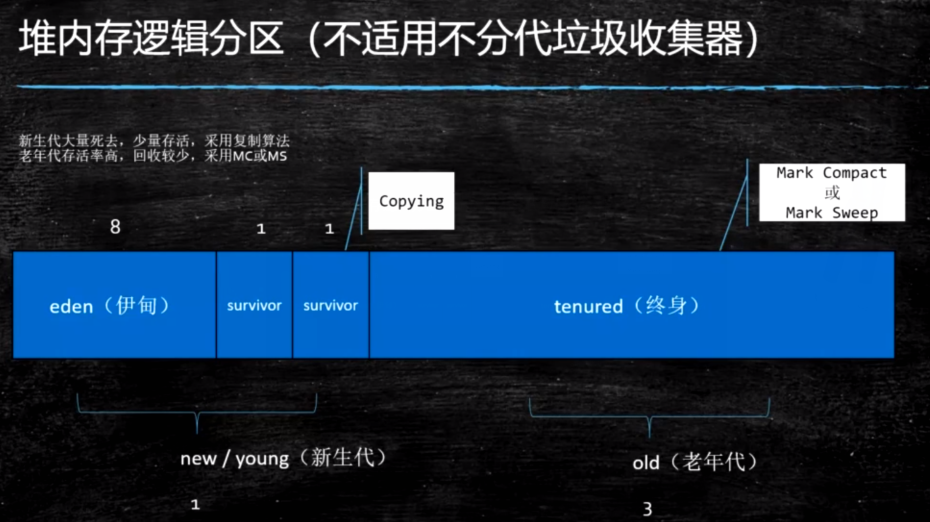
新生代 = Eden + 2个suvivor区
对象首先会被放在栈Stack上,栈上放不下会被放在eden,垃圾回收之后进入survivor,再次垃圾回收会进入另一个survivor,多次gc之后会进入老年代
-
YGC回收之后,大多数的对象会被回收,活着的进入s0
-
再次YGC,活着的对象eden + s0 -> s1
- 再次YGC,eden + s1 -> s0 ,
-
年龄足够 -> 老年代
采用Parallel Scavenge 垃圾回收算法,默认次数是15,存放次数只有4位,最大只能是15
采用CMS默认是6
采用G1默认是15
采用 -XX:MaxTenuringThreshold 指定次数
- s区装不下 -> 老年代
-
-
老年代
- 顽固分子
- 老年代满了FGC Full GC
-
GC Tuning (Generation)
- 尽量减少FGC
- MinorGC = YGC :年轻代空间耗尽时触发 ,-Xmn
- MajorGC = FGC : 在老年代无法继续分配空间时触发,新生代老年代同时进行回收
-
栈上分配,什么情况对象会分配到栈上?
-
线程私有小对象
- 无逃逸: 只在一段代码中使用,其他代码没有用到
- 支持标量替换: 一个对象中只有普通属性,用对象中的普通属性代替对象
-
-
线程本地分配TLAB (Thread Local Allocation Buffer) 调优时建议不调整
创建对象,分配eden内存时,会有多个线程争用内存地址,如果采用同步效率会降低,于是用TLAB来解决这个问题。每个线程分配1%的空间,这个空间是线程独有的
-
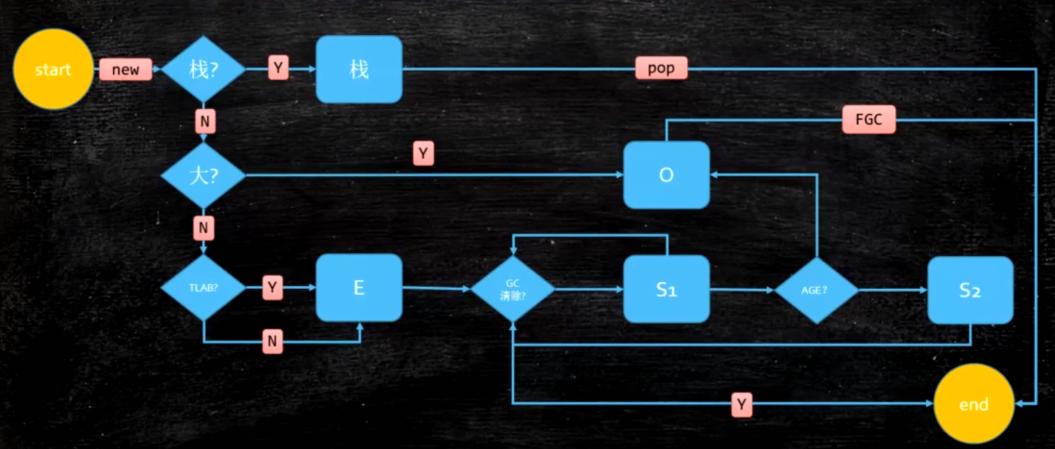
对象分配过程图
对象首先会尝试放在栈Stack上,栈上放得下就放在栈上,如果栈上放不下,再看对象大不大,大的话直接放在Old,小的话放TLAB,TLAB是在Eden区内,进行gc,放入s1区,看年龄够不够,够的话放Old区,不够放S2区
5.常见的垃圾回收器
-
JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS 并发垃圾回收是因为无法忍受STW
-
STW gc时会停止工作进程的方式,除了CMS不是STW类型的,其他方式都是STW的
-
Serial 年轻代 串行回收
单线程 ,在安全点停止工作进程,gc后再恢复工作进程
-
PS 年轻代 并行回收
parallel scavenge 默认的垃圾回收策略,清理线程是多个
-
ParNew 年轻代 配合CMS的并行回收
相对于parallel scavenge加了一些增强,以适用于CMS
-
SerialOld 用于老年代,也是单线程,已淘汰
-
Parallel Old 默认的
-
ConcurrentMarkSweep 老年代垃圾回收器 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms) CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定 CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收
CMS清理垃圾的4个阶段:
- 初始标记: STW,标记根节点
- 并发标记: 标记垃圾,与工作线程并发进行
- 重新标记: STW,标记并发标记过程中新产生的垃圾
- 并发清理: 清理垃圾,与工作进程并发进行,该过程会产生浮动垃圾
- 算法:三色标记 + Incremental Update
G1(10ms)
- G1中的GC收集
- G1保留了YGC并加上了一种全新的MIXGC用于收集老年代。G1中没有Full GC,G1中的Full GC是采用serial old Full GC。 + 算法:三色标记 + SATB
ZGC (1ms) PK C++
- 算法:ColoredPointers颜色指针 + LoadBarrier读屏障
垃圾收集器跟内存大小的关系:
- Serial 几十兆
- PS 上百兆 - 几个G
- CMS - 20G
- G1 - 上百G
- ZGC - 4T - 16T(JDK13)
6.三色标记算法
会用白色,灰色、黑色来标记对象。
- 白色:未被标记的对象
- 灰色:自身被标记,成员变量未被标记
- 黑色:自身和成员变量均已标记完成
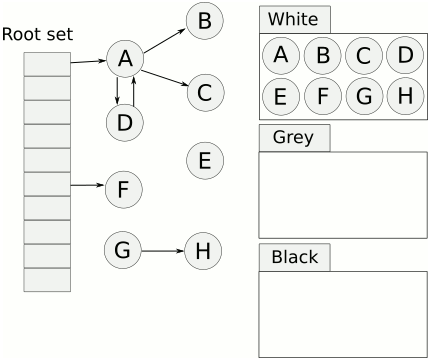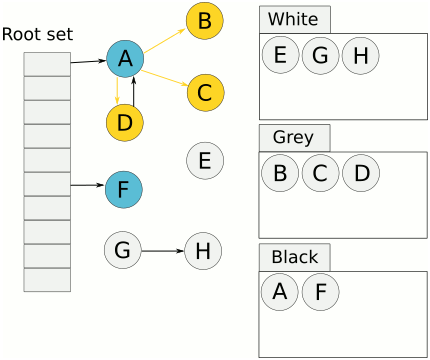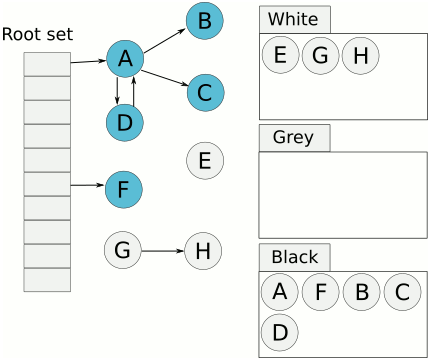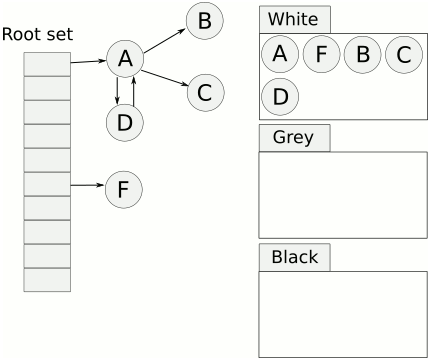
但是会存在漏标问题:
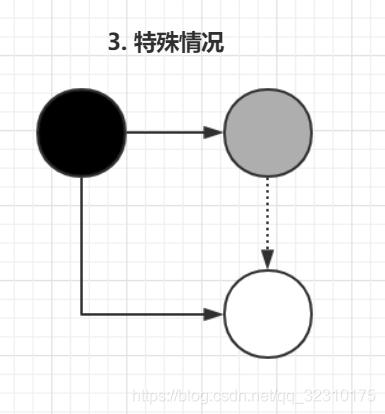
- 在remark过程中,黑色指向白色,如果不对黑色重新扫描,则会漏标,会把白色对象当做没有新引用指向从而被回收掉
- 并发标记过程中,删除了所有从灰色到白色的引用,会产生漏标,此时白色对象应该被回收
漏标的两个充要条件
- 有至少一个黑色对象在自己被标记之后指向了这个白色对象
- 所有的灰色对象在自己引用扫描完成之前删除了对白色对象的引用
为了避免漏标,有以下两种方法:
- incremental update – 增量更新,关注引用的增加,把黑色重新标记为灰色,下次重新扫描属性,CMS采用该方式。会多导致扫描一次。
- SATB snapshot at the begining – 关注引用的删除,当灰色对象对白色对象的引用删除时,要把这个引用推到GC的堆栈中,保证白色对象还能被GC扫描到,相当于把白色标记为灰色。G1采用该方式。会导致浮动垃圾到下一次才回收。
为什么G1用SATB?
灰色->白色 引用消失时,如果没有黑色指向白色,引用会被push到堆栈
下次扫描时拿到这个引用,由于有RSet的存在,不需要扫描整个堆去查找指向白色的引用,效率比较高。